ラビットチャレンジ【機械学習】~線形回帰モデル~
概要
機械学習モデルの一つである線形回帰モデルを知識ベースと実際にデータに触れながら学ぶ
この章では以下の項目を学んだ
・課題解決としての機械学習
・回帰問題の基礎知識
・モデルの説明
・パラメータの推定
・モデルの評価
・ボストンの住宅データセットによるハンズオン
・ロバスト回帰(appendix)
課題解決としての機械学習
昨今のAIブームによって「AIなら何でもできる!!」と盲信する人もいれば「AIの事は信用ならない」と頑なに拒絶する人もいる
しかし、AIはあくまで課題解決方法の1つであるため、何でも100%の解答を出して課題解決ができるわけではない
AIを活用する前に、まず確認することは「この課題はAIによって解答することがベストであるのか?」という問いかけである。(この章であれば機械学習)
機械学習を活用するにしても学習用に収集したデータにバイアスがかかっていないかに注意する必要がある。
機械学習モデルの選定やハイパーパラメータチューニングといったメインとなる部分よりも、大前提となる工程を大切にするべきであると留意したい。
回帰問題の基礎知識
そもそも回帰問題ってなに?
回帰問題とは数値を予想する問題こと。学習時に入力データと出力データから対応する規則を学び、未知の入力データに対して適切な出力結果を生成する手法である
入力データと出力データのペアが与えられる教師あり学習の一つである
その回帰問題を解く一つの手法として線形回帰がある
モデルの説明
線形回帰とは名前の通り直線を引き入力データから出力データを予測するモデルである。説明が2個以上になれば平面や超平面により予測する。
入力データが1次元(1個)の場合の線形回帰モデルの数式は以下のようになる。
w0とw1は未知の値でありパラメータと呼ばれる。機械学習では既知のy(目的変数),x(説明変数)から学習していき、良い予測ができるようにパラメータを更新していく
xの数が変化(多次元化)した場合の線形回帰モデルの数式と入力データ、出力データがどんな形式であるかを以下に示す。画像ではwがaになっている


パラメータの推定
線形回帰モデルのパラメータは最小二乗法で推定する
平均二乗誤差を小さくすることを目的とする(データとモデル出力の二乗誤差の和であり、下写真であれば斜めの点線と青点との距離)
*一般的に二乗損失は外れ値に弱いのでHuber損失やTukey損失でも可能
つまり予測の青点が正解となる点線に近づくようにパラメータを更新していく

学習データの平均二乗誤差の最小は、その勾配が0になる点を求めればよい
以下に平均二乗誤差の公式から勾配を求めるまでの過程をしめす


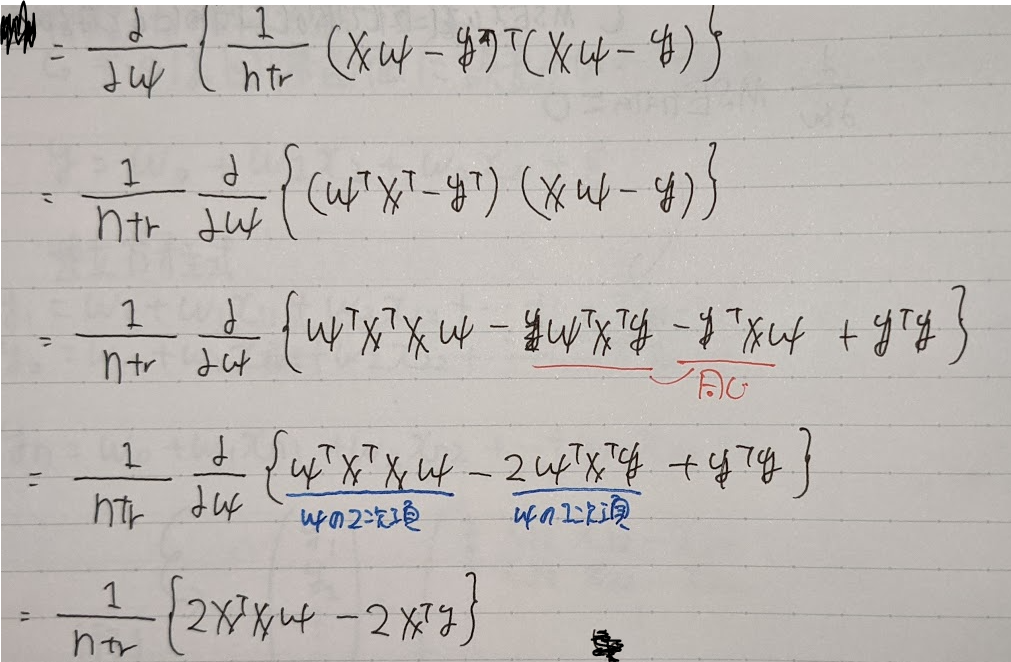

モデルの評価
学習が終了(最適なパラメータに更新完了)で終わりではなく、未知のデータを入れて精度よく予測ができるかを確認する必要がある
AIの目的は未知のデータに対してもきちんと予測することができるか(訓練データだけに上手く予測できても意味がない)。つまり、モデル自体の汎化性能を測定する。
そのため、手元にあるデータ全てを学習用に使用するのではなく、一定のデータを検証用に置いておく必要がある。
学習用のデータでパラメータを更新して、検証用のデータでモデルの汎化性能を測定する

ボストンの住宅データセットによるハンズオン
線形回帰モデルにより学習を行い「部屋数4で犯罪率0.3の住宅価格を予測する」
以下がコードと結果。4.24007956の予測結果が出力された

ロバスト回帰
そもそもロバスト回帰とは?
モデルの訓練に用いるデータに外れ値があった場合に、その外れ値の影響を小さくするような学習方法のこと

予測値と正解の値との絶対値誤差を損失に用いる。外れ値の影響は線形にしか効いてこなくなるため、二乗誤差より外れ値の影響が小さくなる。
外れ値に対してロバストではあるが、逆に外れ値でないどのような点に対しても特に特徴づけず一定に見ている。
線形回帰モデルで使用していた平均二乗誤差はL2損失ともいう
Huber損失
L1損失とL2損失のいいとこ取りをしたような損失関数。 小さい誤差に対しては二乗誤差になり、大きい誤差に対しては絶対誤差を計算するように設計している。

外れ値の影響はゼロではなく線形程度には効いてしまう
Tukey損失
ある程度外れていたらそのデータを完全に無視するように設計された損失
